리뷰 정리
이 연구는 크게 3가지로 나눌 수 있습니다.
- SFT없이 RL만으로 추론 모델 만듦. (RL로 대형 모델 만듦)
- SFT는 시간과 돈을 잡아 먹어. SFT 빼고 모델 학습해.
- RL로 학습해. 정답뿐 아니라, 사고 과정도 평가해.
- 얘 봐라?
- 문제 풀려고 시간도 더 달라고 하고,
- 푸는 와중에 "아하!"라고 사람 말로 외치기도 하고,
- 성능이 GPT보다 더 좋아지기도 하잖아.
- SFT를 추가하면 상기 1을 개선할 수 있음. (RL+SFT로 대형 모델 만듦)
- 상기 2로 만든 데이터셋으로 소형 모델을 SFP하면 엄청 좋음. (SFT로 소형 모델 가르침)
그 중 단연 1번이 돋보이는 이유는 가장 큰 병목(bottleneck)인 supervised의 비용 및 노동 의존을 해소한다는 점입니다. 리딩 기업들이 GPU 수를 늘리고 데이터센터를 더 짓는 등 하드웨어 파워를 늘려 경쟁력을 확보하는 머니게임을 진행하는 와중에 효율 설계라는 소프트 파워로 가능성을 봤다는 점이 흥미롭습니다.
리뷰에 앞서..
오랜만의 논문 리뷰입니다. 실은 논문이 아니라 기술 보고서(technical report)지만요. 업무에 치여 바쁘다는 핑계로 새로운 기술 습득에 소홀했습니다. 기술 동향(tech trend)을 읽고 새로운 기술 습득을 위해서 대략적이나마 큰 그림을 그려(rough mapping), 추후 스터디에 활용할 수 있도록 하겠습니다.

초록 (Abstract)
DeepSeek-R1-Zero와 DeepSeek-R1을 공개합니다. DeepSeek-R1-Zero는 SFT(supervised fine-tuning) 없이 대규모 강화 학습(RL)을 통해 훈련된 모델입니다. RL로 DeepSeek-R1-Zero는 다양한 추론 동작을 자연스럽게 잘 구현하지만, 동시에 가독성 저하(poor readability)와 언어 혼용(lang mixing)같은 문제에 직면합니다. DeepSeek-R1은 멀티 스테이지 학습(multi-stage training)과 콜드 스타트(cold-start data before RL)를 통합하여, 이러한 문제를 해결하고 성능을 향상시켰습니다. DeepSeek-R1은 OpenAI-o1-1217에 견줄 성능을 달성했습니다. DeepSeek-R1-Zero, DeepSeek-R1을 비롯하여 DeepSeek-R1에서 증류(distilled)한 Qwen과 Llama 기반 모델 6개(1.5B, 7B, 8B, 15B, 32B, 70B)를 오픈 소스로 공개합니다.
1. 소개 (Introduction)
1.1. 기여 (Contribution)
사후 학습(Post-Training) : 베이스 모델(DeepSeek-V3)에서 대규모 RL
- DeepSeek-R1-Zero는 베이스 모델에 SFT없이 바로 RL을 적용했습니다. 이 접근 방법은 모델이 생각 사슬(CoT: Chain of Thought)을 탐험(explore)할 수 있도록 허용합니다. 우리는 최초로 이 접근 방법을 검증한 공개 연구입니다.
- DeepSeek-R1을 개발한 파이프라인은 두 RL 단계와 두 SFT 단계를 포함합니다. RL 단계는 개선된 추론 패턴을 발견하고 인간의 선호도에 맞추기 위함이고, SFT 단계는 추론과 비추론 능력의 씨앗(seed)을 제공하기 위함이다.
2. 접근 (Approach)
2.1. 개요 (Overview)
기존에는 대량의 supervised data에 크게 의존했습니다. 우리 연구는 콜드 스타트로서의 그 어떤 SFT 데이터도 사용하지 않고도 RL을 통해 추론 능력을 크게 향상시킬 수 있음을 입증했습니다. 나아가 소량의 콜드 스타트 데이터를 포함하면 성능은 더 개선될 수 있습니다.
2.2. DeepSeek-R1-Zero: RL on the Base Model
우리의 기존 연구도 RL이 추론 작업에서 상당한 효과가 있음을 입증했지만, 이는 supervised data에 매우 의존적이고, 그 supervised data를 모으는 일은 매우 많은 시간이 소요됩니다. 우리는 supervised data없이 순수한 RL 과정을 통해서 스스로 추론 능력을 개발할 수 있는 LLM의 잠재력을 살펴봅니다.
2.2.1. RL 알고리즘(Algorithm)
GPRO (Group Relative Policy Optimization)
새 정책을 옛 정책과 비교해 보상이 커지는 방향으로 업데이트하되, 클리핑과 KL페널티로 지나치게 크게 변하지 않도록 제한한다.
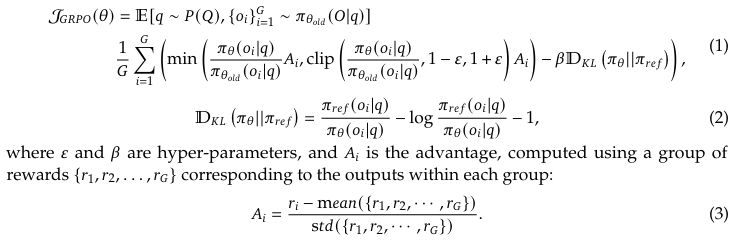
2.2.2. 보상 모델링(Reward Modeling)
크게 두 가지 유형의 보상으로 구성된 규칙 기반 보상 시스템을 채택했습니다.
- 정확도 보상 (Accuracy reward) : 정답 여부 평가
- 형식 보상 (Format reward) : <think>와 </think> 사이에 사고 과정을 넣도록 강제하는 형식 보상 모델 사용
결과 또는 과정 보상 (outcome or process neural reward): 학습 과정에서 보상 해킹(reward hacking)이 발생할 수 있고, 보상 모델을 재학습하려면 추가 학습 자원이 필요하며, 전체 학습 파이프라인이 복잡해지기 때문에 적용하지 않았습니다. (뒤 Discussion에서 자세히 설명함.)
2.2.3. 학습 템플릿(Training Template)
먼저 기본 모델이 지정된 지침을 준수하도록 안내하는 간단한 템플릿을 설계하여 DeepSeek-R1-Zero를 훈련합니다. 하기 템플릿처럼 DeepSeek-R1-Zero가 먼저 추론 프로세스를 생성한 다음 최종 답변을 생성하도록 요구합니다.
A conversation between User and Assistant.
The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.
User: prompt.
Assistant:
2.2.4. 성능, 자기 진화 과정, 아하! 모먼트 (Performance, Self-evolution process and Aha moment)
성능
AIME2024 데이터셋에 대하여 평균 합격률은 초기 15.6%에서 71.0%로 크게 상승하여 OpenAI-o1-0912와 비슷한 성능 수준에 도달했습니다. 나아가 투표(voting)를 적용하면 71.0%에서 86.7%로 상승하여 OpenAI-o1-0912를 능가합니다.

자기진화과정
RL을 통해서 모델은 외부 개입 없이 스스로 사고 시간을 지속적으로 연장합니다. 이 테스트 시간 연장을 활용하여 점점 더 복잡한 추론 작업을 해결할 수 있는 능력을 자연스럽게 습득합니다. 놀랍게도 모델이 이전 단계를 재검토하고 재평가하는 성찰과 문제 해결을 위한 대안적 접근 방식의 탐색과 같은 행동이 자연스럽게 발생합니다. 이 모든 것이 명시적으로 프로그래밍된 것이 아니라 모델이 RL과 상호 작용한 결과로 나타납니다.

아하!모먼트
모델이 스스로 고급 문제 해결 전략을 개발합니다. 모델이 의인화된 어조를 사용하여 다시 생각하는 법을 배운다는 것은 매우 흥미롭습니다.
Wait, wait. Wait. That's an aha moment I can flag here.
(잠깐, 잠깐만요. 잠!깐!만!요! 아하, 이제야 깨달은 순간이네요.)
단점
가독성 저하 및 언어 혼용과 같은 문제로 어려움을 겪었습니다. 이에 추론 프로세스의 가독성을 높이고 인간 친화적인 콜드 스타트 데이터로 RL을 활용하여 DeepSeek-R1으로 개선했습니다.
2.3. DeepSeek-R1: 콜드 스타트와 함께 RL
DeepSeek-R1-Zero에서 영감을 받아 두 가지 질문으로 이어졌습니다.
1) 소량의 고품질 데이터를 콜드 스타트로 통합하여 모델을 개선할 수 있을까?
2) 명확하고 일관된 CoT, 강력한 일반 성능. 두 가지 모두 잘하는 사용자 친화 모델을 훈련시킬 방법은?
그 답으로, ReepSeek-R1을 훈련시키는 4단계 파이프라인을 설계했습니다.
2.3.1. Cold Start
Zero 모델과 달리, 수천개의 긴 CoT 데이터를 수집하여 RL 학습의 초기 불안정한 콜드 스타트 단계를 방지했습니다. 이 데이터를 수집하기 위해,
1) 긴 CoT를 예시로 한 few-shot 프롬프팅
2) 반성, 검증과 구체적인 답변을 생성하도록 직접 프롬프팅
3) Zero 모델의 readable 포맷을 수집
4) 인간의 후처리로 결과를 개선하는 방법
등을 사용했습니다.
콜드 스타트를 통해서 가독성과 잠재성의 개선을 이뤘습니다. 잠재성은 Human Prior가 있는 콜드 스타트 데이터 패턴을 신중하게 설계할 수 있다는 점입니다.
2.3.2. 추론 지향 RL
콜드 스타트로 fine-tuning한 후, Zero 모델 학습에 사용한 것과 동일한 대규모 RL 을 진행합니다. 언어 혼용 문제를 완화하기 위해서 RL 훈련 중에 언어 일관성 보상을 도입했으며, 이는 CoT에서 목표 언어 단어의 비율로 계산됩니다. 실험 결과 이러한 보상은 성능을 약간 저하시키지만, 사람의 선호도와 일치하여 가독성을 높여줍니다.
2.3.3. 거절 샘플링 (Rejection Sampling)과 SFT
추론 지향 RL이 수렴하면, 다음 라운드를 위한 SFT 데이터를 수집합니다. 콜드 스타트 데이터가 추론에 집중한다면, 이 단계는 작문, 역할, 기타 일반 작업 수행을 위한 다양한 도메인 데이터를 포함합니다.
추론 데이터는 이전 RL 훈련에서 얻은 체크포인트를 활용하여 거절 샘플링을 수행함으로써, 추론 경로를 생성합니다. 이전 단계에서는 규칙 기반 보상으로 평가할 수 있는 데이터만 포함했지만, 이번 단게에서는 확장합니다. 언어 혼합 CoT, 너무 긴 단락, 코드 블록이 포함된 응답은 필터링하였습니다. 결과적으로 약 60만 개의 추론 데이터를 수집하였습니다.
비추론 데이터는 DeepSeek-V3 파이프라인을 활용하며, 동 모델의 SFT 데이터셋 일부를 재사용합니다. 최종적으로 약 20만 개의 비추론 데이터를 수집하였습니다.
2 에포크 동안 상기 80만개 데이터로 fine-tuning을 진행합니다.
2.3.4. RL을 모든 시나리오로 확장
모델을 인간의 선호에 더욱 맞추기 위해, 우리는 보조 강화 학습 단계를 도입합니다. 보상 신호와 다양한 데이터 분포를 통합함으로써, 뛰어난 추론 능력을 갖추면서도 유용성과 무해성을 우선하는 모델을 학습할 수 있습니다.
2.4. 증류: 추론 능력으로 작은 모델을 강하게
DeepSeek-R1과 같은 강력한 추론 능력을 보다 효율적인 소형 모델에 적용하기 위해, 우리는 DeepSeek-R1을 활용하여 선별된 80만 개의 샘플을 기반으로 오픈소스 모델인 Qwen(Qwen, 2024b)과 Llama(AI@Meta, 2024)를 직접 미세 조정(fine-tuning) 하였습니다. 단순한 지식 증류(distillation) 방법만으로도 소형 모델의 추론 능력이 크게 향상됨을 확인하였습니다. 증류된(distilled) 모델의 경우, SFT(지도 학습 기반 미세 조정)만을 적용하고, RL(강화 학습) 단계는 포함하지 않았습니다.
'개발' 카테고리의 다른 글
| YOLOv5 C3 Block 시각화 리뷰 (0) | 2025.03.28 |
|---|---|
| Deep Residual Learning for Image Recognition: ResNet 시각화 리뷰 (0) | 2025.03.25 |
| 라즈베리파이4와 스텝 모터 드라이버 연결 및 문제 해결 과정 (1) | 2025.01.03 |
| Next.js Introduction (0) | 2024.04.20 |
| GPT기반 카카오톡 AI챗봇 해몽해드림 개발기 1(미완성) (1) | 2024.02.10 |