KAIST 연구진의 초해상도(super resolution) AI 논문 "Chain-of-Zoom: Extreme Super-Resolution via ScaleAutoregression and Preference Alignment" 입니다.

- 논문 링크 : arXiv:2505.18600
- 플젝 링크 : https://bryanswkim.github.io/chain-of-zoom/
1 | 사진을 크게 키우면 왜 깨질까?
오래된 사진을 스마트폰으로 찍어 확대해 보면 얼굴이 금세 흐릿해집니다. 초해상도(Super-Resolution, SR)는 이 흐릿해진 부분의 사이를 그려넣어서 자연스럽게 만드는 작업입니다.
기존 SR 모델은 대부분 “4배 전용” 같이 고정된 배율만 잘 다룹니다. 그래서 4배 모델에 16배 확대를 시키면 블러나 가짜 질감이 생기죠.
2 | KAIST Chain-of-Zoom(CoZ)이 택한 똑똑한 방법
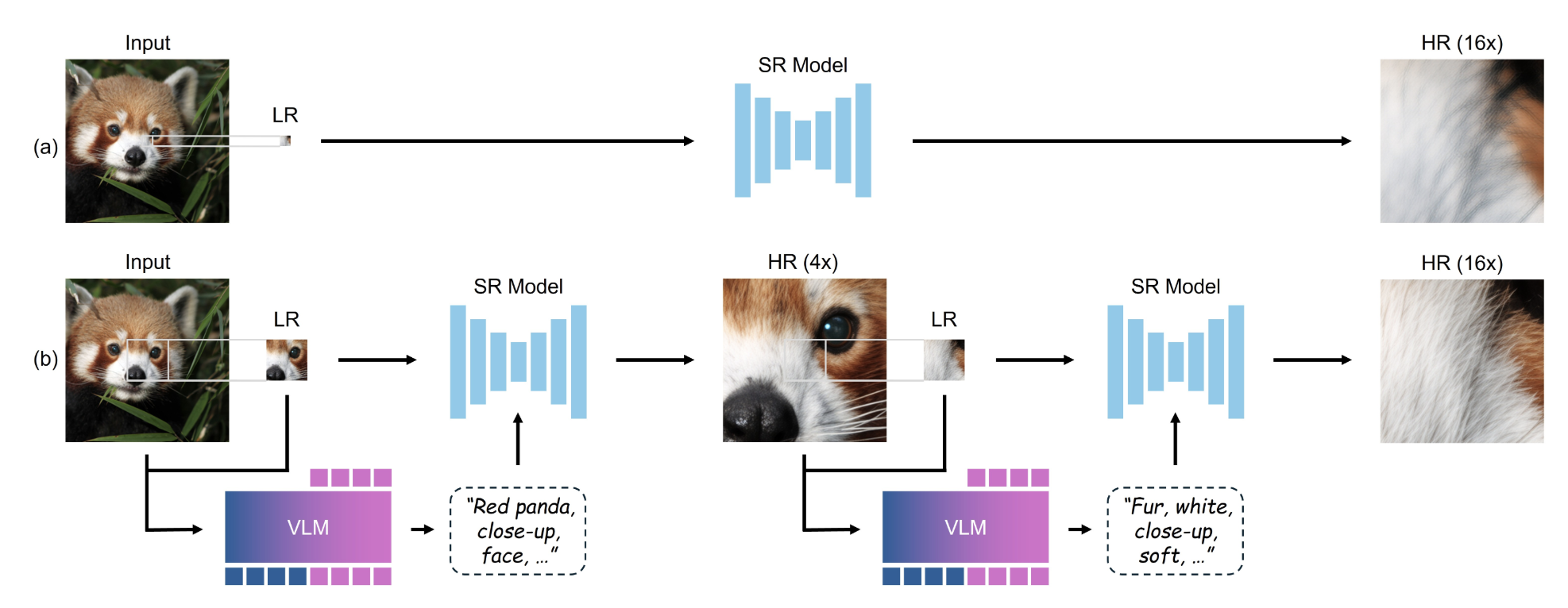
2-1 ⎮ 4배 × 4배 × 4배 (AR-2)
한 번에 64배를 시도하지 말고 4배씩 여러 번 확대합니다.
기존 4배 모델을 재사용하니 64배·256배까지도 품질이 무너지지 않습니다.
2-2 ⎮ 사진 + ‘짧은 설명’
확대할수록 원본 정보는 줄어듭니다.
CoZ는 매 단계마다 짧은 캡션(예: “나뭇잎 결”, “고양이 털”)을 넣어 AI가 논리적 디테일을 유지하도록 돕습니다.
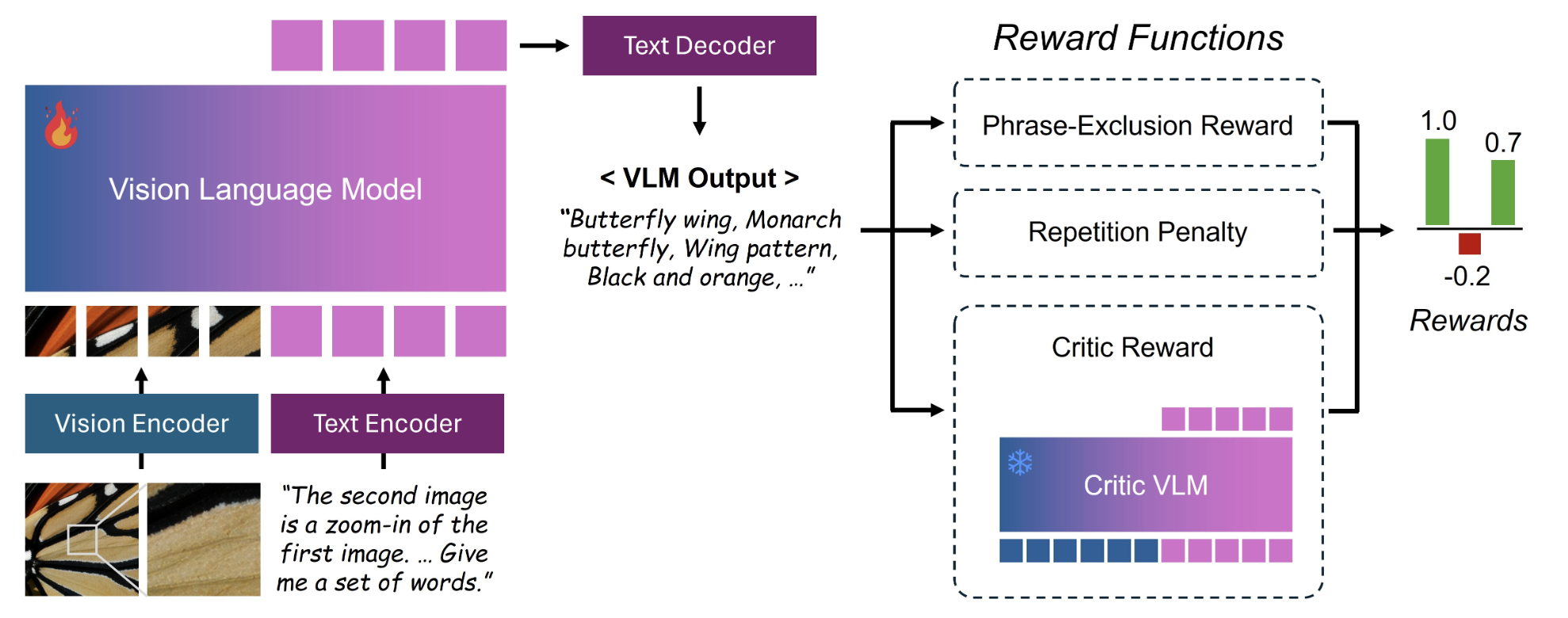
2-3 ⎮ AI 작가 & AI 코치
| 역할 | 비유 | 논문 용어 |
|---|---|---|
| AI 작가 | 설명을 써 주는 사람 | prompt-extraction VLM |
| AI 코치 | 설명을 채점하는 심판 | $$R_{critic}$$ |
| 불필요어 감점 | “첫 이미지…” 제외 | $$R_{phrase}$$ |
| 반복 감점 | 같은 단어 되풀이 감점 | $$R_{rep}$$ |
1. AI 작가가 설명 생성
2. AI 코치가 점수 부여
3. 점수가 보상이 되어 학습이 진행됩니다 — 이것이 GRPO 기반 RLHF 방식입니다.
보상 공식:
$$ R(c_i) = w_{critic} \cdot R_{critic} + w_{phrase} \cdot R_{phrase} + w_{rep} \cdot R_{rep} $$
3 | 결과 한눈에 보기
- 256배 확대에서도 선명한 디테일 확보
- 새 모델 훈련 필요 없어 메모리·시간 절약
- 캡션 덕분에 가짜 무늬·왜곡 감소
4 | 한 줄 요약
Chain-of-Zoom은 AR 모델 재사용과 해설가+GPRO를 더해, 어떤 사진도 자연스럽게 초고해상도로 복원합니다.
'개발 > AI' 카테고리의 다른 글
| AI, 정말 생각하는 걸까? – Apple vs Claude(Opus)의 추론 논쟁 정리 (1) | 2025.06.17 |
|---|---|
| DETR 논문 리뷰 End-to-End Object Detection with Transformers (7) | 2025.06.06 |
| YOLOv5 C3 Block 시각화 리뷰 (0) | 2025.03.28 |
| Deep Residual Learning for Image Recognition: ResNet 시각화 리뷰 (0) | 2025.03.25 |
| 딥시크(DeepSeek-R1-Zero) 논문 리뷰 (0) | 2025.01.31 |